Next: Introducing RDFS & OWL
Whilst RDF offers a flexible, graph-based model for recording data that is interchangable globally, it doesn’t offer any means to record semantics or meaning. Saving technical specifics for the next lesson, let’s make a review of the models of data which are commonly available and explain what all the fuss is about.
After this tutorial, you should be able to:
- Compare and contrast the properties of the various data modeling types and their typical scope.
- Recognise the benefits that the semantic web model offers over traditional modeling approaches.
- Understand the terms vocabulary and ontology in semantic web terms.
- Understand the role of metadata initiatives (e.g. Dublin Core) in standardizing information interchange.
Estimated time: 5 minutes
You should have already understood the following lesson (and pre-requisites) before you begin:
- Tutorial 2: Introducing RDF
There are various popular, mainstream ways to model data, some of which have emerged later than others. Before exploring the benefits of the RDF model, it is best to make a review of some of the approaches to modeling data that have already been established.
Look at the table below which makes an easy comparison between the approaches and highlights some of the unique qualities of the semantic data model.
| Model | Example Format | Data | Metadata | Identifier | Query Syntax | Semantics (Meaning) |
| Object Serialization | .NET CLR Object Serialization | Object Property Values | Object Property Names | e.g. Filename | LINQ | N/A |
| Relational | MS SQL, Oracle, MySQL | Table Cell Values | Table Column Definitions | Primary Key (Data Column) Value | SQL | N/A |
| Hierarchical | XML | Tag/Attribute Values | XSD/DTD | e.g. Unique Attribute Key Value | XPath | N/A |
| Graph | RDF/XML, Turtle | RDF | RDFS/OWL | URI | SPARQL | Yes, using RDFS and OWL |
Metadata is a term you will come across again and again when harnessing semantic web technologies. “Metadata” is not a complex term or concept – it simply means “data about data” (taken from the Greek meta- meaning “after”). The table above shows some examples of how you might classify the metadata for various different models.
3.2 Why Include Semantics In Data? Knowledge Integration
There’s no point in adding semantics to your data if it does not provide significant benefits. One of the primary benefits of adding semantic meaning to your data is that it can be branched across domains of knowledge automatically. What do we mean domains of knowledge? Let’s illustrate using a simple example.
In our example, two websites are started independently from each other. One site hosts information on current and historic Oscar winning films; the other a large database of biographies of Hollywood actors and actresses.
Both contain complementary information in their website databases. We will cover firstly how information sharing between these sites could happen without the use of semantics. Then, we will describe how the same information can be shared between the two sites – and potentially beyond – with the use of semantics.
Sharing Without Semantic Modeling
Our two sites, one fronting an MS SQL database of all Oscar winning films, and another one fronting a MySQL database of Hollywood actors, reside at http://www.oscarwinners.fake and http://www.actorbiographies2go.fake respectively. The two sites were started independently, and do not collaborate.
The Oscar Winners site lists, as its name suggests, all of the Oscar winning films ever produced and also a list of actors and actresses who starred in them. However, it doesn’t hold any other actor information other than their name and date of birth.
The Actor Biographies site contains a complete listing of many current and former Hollywood actors, including a complete biography, plus a list of movies that they starred in. But, it does not contain any film plots, or screenshots of the films.
Let’s look at how these two sites might collaborate under their current, more traditional data model:
- Obviously, the users of http://www.oscarwinners.fake would benefit from being able to click on the name of a starring actor and find out more about them – this information is stored in the MySQL database at http://www.actorbiographies2go.fake.
- Likewise, the users of http://www.actorbiographies2go.fake would benefit from being able to click on the names of films that the actors starred in and find more information. This is stored in the MS SQL database at http://www.oscarwinners.fake.
- Any sharing of data between the two sites cannot be done by joining tables in their databases. Firstly, they have been independently designed in the first place and so their primary keys referring to individual actors or films in both databases will not be synchronized. They would have to be mapped. But secondly, they are using different database server systems which are not cross-compatible.
- To collaborate using their current databases, the owners of either site would have to decide on a common data format by which to share information that they could both understand by using a common film and actor unique ID scheme of their own invention. They could do this, for example, by creating a secure XML endpoint on each of their websites from which they can request information from each other on demand. This way, their shared information is always up to date.
Important Point This sort of information interchange across incompatible, independently designed data systems takes time, money and human contextual interpretation of the different datasets. It also is restrictive to the data domains of only these two websites, any further additions to their knowledge from elsewhere will demand similar efforts. It requires humans to understand the meaning of the data and agree on common formats to collaborate the two databases appropriately.
With the introduction of RDF and semantics, it is far easier. Let’s investigate how this could be achieved using RDF and the semantic web – it all happens automatically, not manually.
Sharing With The Semantic Web Model
In semantic modeling, the following are important terms you should know:
- Vocabulary – A collection of terms given a well-defined meaning that is consistent across contexts.
- Ontology – Allows you to define contextual relationships behind a defined vocabulary. It is the cornerstone of defining a knowledge domain. A formal syntax for defining ontologies is OWL (Web Ontology Language) which is an extension to RDFS (RDF Schema), which we shall formally introduce in the next lesson.
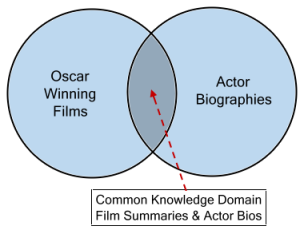
So how do we model the two site scenario using semantic modeling? Firstly, the two sites need to apply a common, standard vocabulary to describe their data that is contextually consistent. For example, the term ‘film title’ should mean the same thing for both sites, as should the term ‘actor name’ and ‘actor birthdate’.
This may be done by the two sites adopting the same base ontology, or a common vocabulary, for expressing the meaning behind the data they expose, and publishing that data on a queryable endpoint so that the two sites can communicate with each other across the web.
With this standard vocabulary in place:
- The two sites can now query each other using the same terms.
- The Oscar Winning Movies site can now query the actor names on the Actor Biographies site on-demand and gain more detail about a specific actor or actress that has starred in a movie.
- The Actor Biographies site can now query the film plots on the Oscar Winning Movies site on-demand and gain more detail about films an actor has starred in.
- With the contextual relationships defined in a formal web ontology, further related information about the actors or films, e.g. film locations, other news events happening on the same day of filming or birthdate or the actor, or films made by the same director, may be found via the linked standard terminology without the user even imagining that information initially existed.
- This happens without the need for transformation, mapping, or contracts being set up between the two sites. It all happens through semantics.
We’ll see in the next lesson what the makeup of a semantic web ontology is, how you query a semantic database and even perform machine inference on it.
Point Of Interest The good news is you often won’t have to go through the effort of defining and sharing your own ontology for your particular domain of knowledge. There are many popular, standard ontologies already distributed on the web which you can adopt, and if necessary extend yourself. We will introduce some of these in the following section.
The cross-domain knowledge sharing discussed here need not just apply to websites, but also within the knowledge bases built by organisations. Semantic web technologies need not be restricted to applications or information published on the web.
Although there may be a little more groundwork required when first setting up a semantic database, the benefits for ease of cross-domain integration from across the globe and the time saved and ideas gained from doing so are, potentially, highly significant.
3.3 Metadata Initiatives
Standard vocabularies, or formal ontologies representing terms within a domain of knowledge, are already available freely from various organisations dedicated to creating standard vocabularies for a range of subjects – for example media terms, or biomedical terms, or scientific terms. Below are some examples:
- Dublin Core Metadata Initiative (DCMI) – Creates ontologies for a range of subjects, particularly focusing on common, every day terms and terms important in media.
- Friend Of A Friend (FOAF) – focuses on developing a standard vocabulary/ontology for social networking purposes.
- OpenCyc – An ontology of everyday, common sense terms.
You have now completed this lesson. In the next lesson, we will go into more thorough technical detail into how ontologies are defined in the semantic web, and how semantic web databases can be queried for information.
You have completed this lesson. You should now understand the following:
- The main benefits of semantic data over traditional data models.
- How a semantic web application might function to automatically link data between independent data sources covering the same base of knowledge.
- That open standards for common, everyday vocabulary currently exist.
You should now be able to start the following tutorial:
- Tutorial 4: Introducing RDFS & OWL